

6.5 哈夫曼树
理解哈夫曼树的定义及算法的基本思想,给定一些带权叶子结点,能手工建立哈夫曼树,并求出叶子结点的哈夫曼编码。
1.基本概念
(1)路径和路径长度
若在一棵树中存在着一个结点序列k1、k2、…、kj,使得ki是ki+1的双亲(1≤i<j),则称此结点序列是从k1到kj的路径(Path)。因树中每个结点只有一个双亲结点,所以它也是这两个结点之间的唯一路径。从k1到kj所经过的分支数称为这两点之间的路径长度(path length),它等于路径上的结点数减1。如在图6-9(a)所示的二叉树中,从树根结点A到叶子结点G的路径为结点序列A、E、F、G,路径长度为3。
(2)结点的权和带权路径长度
在许多应用中,常常将树中的结点赋上一个有着某种实际意义的实数,我们称此实数为该结点的权(weight)。结点的带权路径长度(weighted path length,WPL)规定为从树根结点到该结点之间的路径长度与该结点上权的乘积。
(3)树的带权路径长度
树的带权路径长度定义为树中所有叶子结点的带权路径长度之和,通常记为:
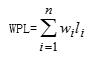
其中n表示叶子结点的数目,wi和li分别表示叶子结点ki的权值和树根结点到ki之间的路径长度。
2.哈夫曼树的定义
哈夫曼树(huffman tree)又称作最优二叉树。它是n个带权叶子结点构成的所有二叉树中,带权路径长度WPL最小的二叉树。因为构造这种树的算法最早是由哈夫曼于1952年提出的,所以被称之为哈夫曼树。
例如,有四个叶子结点a、b、c、d,分别带权为9、4、5、2,由它们构成的三棵不同的二叉树(当然还有其他许多种)分别如图6-11(a)、6-11(a)和6-11(c)所示。
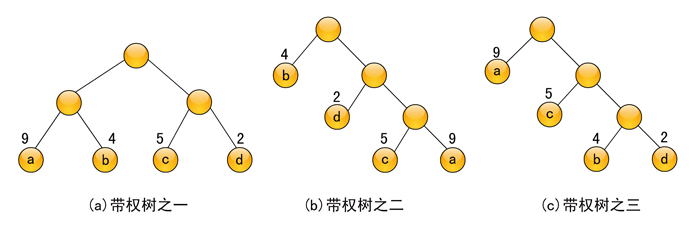
图6-11 由四个叶子结点构成的三棵不同的带权二叉树
这三棵二叉树的带权路径长度WPL分别为:
(a) WPL=9×2+4×2+5×2+2×2=40
(b) WPL=4×1+2×2+5×3+9×3=50
(c) WPL=9×1+5×2+4×3+2×3=37
其中图6-11(c)树的WPL最小,此树就是哈夫曼树。
从上面可以看出,根据n个带权叶子结点所构成的二叉树中,满二叉树或完全二叉树不一定是最优二叉树。权值越大的结点离树根越近(即路径长度越短)的二叉树才是最优二叉树。
3.哈夫曼树的性质
1.除叶结点外,每个结点的度数都为2
2.叶结点数比非叶结点数多1
例:哈夫曼树有10个叶子结点,该树共有19个结点
4.构造哈夫曼树
(1)构造哈夫曼树的过程
给定n个权值的集合W={w1,w2,….wn}
1.在W中选取两个最小的权作为兄弟结点,以它们的权值之和作为其父结点,得到一棵新树;
2.在W中删除上述已选取的权值,以它们的权值之和作为新的权值加入W中;
3.在已构造的二叉树中重复①、②,直至W中只含有一个权重值,这棵二叉树就是所要建立的哈夫曼树(构造出有n个叶结点,叶结点相应的权值为w1,w2…wn的一棵树)
想一想:哈夫曼树唯一吗?
解题分析:
不唯一。因为在构造哈夫曼树的过程中,新树的左子树和右子树可以任意安排,这样就会得到不同结构的多棵哈夫曼树。
假定仍采用图6-11中的四个带权叶子结点来构造一棵哈夫曼树,按照上述算法,则构造过程如图6-12所示,其中图6-12(d)就是最后生成的哈夫曼树,它的带权路径长度为37,由此可知,图6-11(c)是由所给的4个带权叶子结点生成的一棵哈夫曼树。
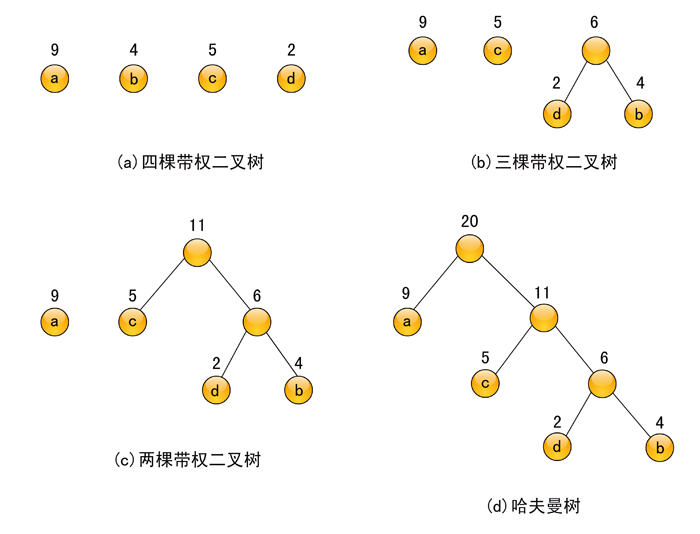
图6-12 构造哈夫曼的过程
在构造哈夫曼树的过程中,每次由两棵权值最小的树生成一棵新树时,新树的左子树和右子树可以任意安排,这样将会得到具有不同结构的多个哈夫曼树,但它们都具有相同的带权路径长度。为了使得到的哈夫曼树的结构尽量唯一,通常规定生成的哈夫曼树中每个结点的左子树根结点的权小于等于右子树根结点的权。上述哈夫曼树的构造过程就是遵照这一规定进行的。
(2)构造哈夫曼树的算法描述
根据上述构造哈夫曼树的过程可以写出相应的用C语言描述的算法,具体如下:
【算法6-13】 构造哈夫曼树算法
struct BTreeNode* CreateHuffman(int a[], int n)
/*根据数组a中n个权值建立一棵哈夫曼树,返回树根指针*/
{
int i,j;
struct BTreeNode **b,*q;
/*动态分配一个由b指向的指针数组*/
b=calloc(n, sizeof(struct BTreeNode*));
/*初始化b指针数组,使每个指针元素指向a数组中对应元素的结点*/
for(i=0; i<n; i++) {
b[i]=malloc(sizeof(struct BTreeNode));
b[i]->data=a[i]; b[i]->left=b[i]->right=NULL;
}
/*进行n-1次循环建立哈夫曼树*/
for(i=1; i<n; i++) {
/*用k1表示森林中具有最小权值的树根结点的下标*/
/*用k2表示森林中具有次最小权值的树根结点的下标*/
int k1=-1,k2;
/*让k1初始指向森林中第一棵树,k2初始指向森林中第二棵树*/
for(j=0; j<n; j++) {
if(b[j]!=NULL && k1==-1) {k1=j; continue;}
if(b[j]!=NULL) {k2=j; break;}
}
/*从当前森林中求出最小权值树和次最小权值树*/
for(j=k2; j<n; j++) {
if(b[j]!=NULL) {
if(b[j]->data<b[k1]->data) {k2=k1; k1=j;}
else if(b[j]->data<b[k2]->data) k2=j;
}
}
/*由最小权值树和次最小权值树建立一棵新树,q指向树根结点*/
q=malloc(sizeof(struct BTreeNode));
q->data=b[k1]->data+b[k2]->data;
q->left=b[k1]; q->right=b[k2];
/*将指向新树的指针赋给b指针数组中k1位置,k2位置置为空*/
b[k1]=q; b[k2]=NULL;
}
/*删除动态建立的数组b*/
free(b);
/*返回整个哈夫曼树的树根指针*/
return q;
}
在这个算法中有多处动态分配存储空间,按正常情况需要判断分配是否成功,这里为简便起见而省略了。不过,由于计算机操作系统的功能越来越强,即使内存无动态分配的空间可用,系统也会自动到外存寻找空间并进行有效分配,所以通常没有必要判断动态分配是否有效。万一分配失败,也不会造成机器故障,系统会自动退出程序运行。
(3)求哈夫曼树的带权路径长度的算法描述
下面给出求哈夫曼树带权路径长度的算法。
【算法6-14】 求哈夫曼树的带权路径长度的算法
int WeightPathLength(struct BTreeNode* FBT, int len)
/*根据FBT指针所指向的哈夫曼树求出带权路径长度,len初值为0*/
{
if(FBT==NULL) return 0; /*空树则返回0*/
else {
/*访问到叶子结点时返回该结点的带权路径长度,其中值参len保存当前被访问结点的路径长度*/
if(FBT->left==NULL && FBT->right==NULL) {
return FBT->data*len;
}
/*访问到非叶子结点时进行递归调用,返回左、右子树的带权路径长度之和,向下深入一层时len值增1*/
else {
return WeightPathLength(FBT->left,len+1)+WeightPathLength(FBT->right,len+1);
}
}
}
5.哈夫曼编码
哈夫曼树的应用很广,哈夫曼编码就是其中的一种。
在电报通讯中,电文是以二进制的0、1序列传送的。在发送端需要将电文中的字符序列转换成二进制的0、1序列(即编码),在接收端又需要把接收的0、1序列转换成对应的字符序列(即译码)。
(1)等长编码
最简单的二进制编码方式是等长编码。例如,假定电文中只使用A、B、C、D、E、F这6种字符,若进行等长编码,它们分别需要三位二进制字符,可依次编码为000、001、010、011、100、101。若用这6个字符作为6个叶子结点,生成一棵二叉树,让该二叉树中每个分支结点的左、右分支分别用0和1编码,从树根结点到每个叶子结点的路径上所经分支的0、1编码序列应等于该叶子结点的二进制编码,则对应的编码二叉树如图6-13所示。
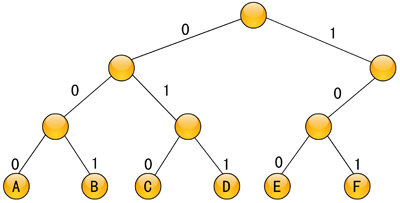
图6-13 编码二叉树
由常识可知,电文中每个字符的出现频率(即次数)一般是不同的。假定在一份电文中,这6个字符的出现频率依次为4、2、6、8、3、2,则电文被编码后的总长度L可由下式计算得到:
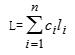
其中n表示电文中使用的字符种数,ci和li分别表示对应字符ki在电文中的出现频率和编码长度。结合我们的例子,可求出L为:
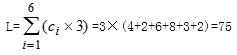
可知,采用等长编码时,传送电文的总长度为75。
(2)不等长编码
现在讨论如何能缩短传送电文的总长度,从而节省传送时间呢?我们自然想到,若采用不等长编码,让出现频率高的字符具有较短的编码,让出现频率低的字符具有较长的编码,这样有可能缩短传送电文的总长度。采用不等长编码要避免译码的二义性或多义性。假设用0表示字符D,用01表示字符C,则当接收到编码串…01…,并译到字符0时,是立即译出对应的字符D,还是接着与下一个字符1一起译为对应的字符C,这就产生了二义性。因此,若对某一字符集进行不等长编码,则要求字符集中任一字符的编码都不能是其他字符编码的前缀。符合此要求的编码叫做无前缀编码。显然等长编码是无前缀编码,这从等长编码所对应的编码二叉树也可直观地看出,任一叶子结点都不可能是其他叶子结点的双亲,也就是说,只有当一个结点是另一个结点的双亲时,该结点的字符编码才会是另一个结点的字符编码的前缀。
为了使不等长编码成为无前缀编码,可用该字符集中的每个字符作为叶子结点生成一棵编码二叉树,为了获得传送电文的最短长度,可将每个字符的出现频率作为字符结点的权值赋予该结点,此树的最小带权路径长度就等于传送电文的最短长度。因此,求传送电文的最短长度问题就转化为求由字符集中的所有字符作为叶子结点,由字符的出现频率作为其权值所产生的哈夫曼树的问题。
根据上面所讨论的例子,生成的编码哈夫曼树如图6-14所示。由编码哈夫曼树得到的字符编码称作哈夫曼编码(Huffman Code)。在图6-14中,A、B、C、D、E、F这6个字符的哈夫曼编码依次为:00、1010、01、11、100、1011。电文的最短传送长度为:
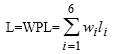
=4×2+2×4+6×2+8×2+3×3+2×4
=61
显然,这比等长编码所得到的传送电文总长度75要小得多。
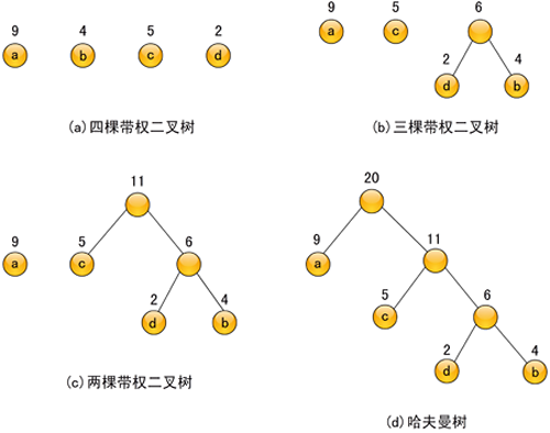
图6-14 编码哈夫曼树
(3)求哈夫曼编码的算法描述
对已经介绍过的求哈夫曼树的带权路径长度的算法略加修改,就可以得到哈夫曼编码的算法描述,具体给出如下。
【算法6-15】 求哈夫曼编码算法
void HuffManCoding(struct BTreeNode* FBT, int len)
/*根据FBT所指向的哈夫曼树输出每个叶子的编码,len初值为0*/
{
/*定义一个静态数组a,保存一个叶子的编码,数组的长度要
至少等于哈夫曼树的深度减1*/
static int a[10];
if(FBT!=NULL) {
/*访问到叶子结点时输出其保存在数组a中的0和1序列编码*/
if(FBT->left==NULL && FBT->right==NULL) {
int i;
printf("结点权值为%d的编码:",FBT->data);
for(i=0; i<len; i++) printf("%d ",a[i]);
printf("\n");
}
/*访问到非叶子结点时分别向左、右子树递归调用,并把分支上的
0、1编码保存到数组a的对应元素中,向下深入一层时len值增1*/
else {
a[len]=0; HuffManCoding(FBT->left,len+1);
a[len]=1; HuffManCoding(FBT->right,len+1);
}
}
}
最后修改: 2019年09月10日 Tuesday 13:41